mysql 学习笔记
-基础笔记-
二次回顾,学校课程 + 慕课网 MySQL 详细学习笔记
包括 MySQL 架构,MySQL 操作,数据类型,数据库操作,数据表操作(创增删改查排序分组)及子句操作
相关术语
DB:数据库(Database)
DBS:数据库系统(Database System)
DBMS:数据库管理系统(Database Management System)
SQL 语言:
- DDL 数据定义语言
- DML 数据操作语言
- DQL 数据查询语言
- DCL 数据控制语言
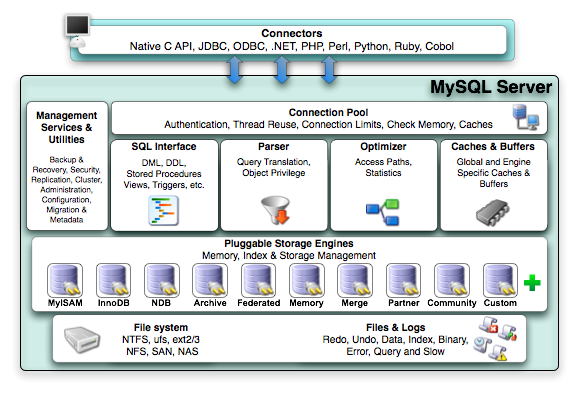
MySQL 架构
MySQL 是由 SQL 接口、解析器、优化器、缓存和存储引擎组成
- Connectors 指的是不同语言与 SQL 的交互接口
- Management Serivices & Utillities 系统管理和工具
- Connection Pool 连接池,管理缓冲用户连接,线程处理等需要缓存的需求
- SQL Interface 接收用户的 SQL 指令,并且返回需要查询的结果
- Parser 解析器
- Optimizer 查询优化器 选取-投影-联接
- Caches & Buffers 查询缓存
- Engine 存储引擎
MySQL 存储引擎(loading…)
memory 存储引擎
CSV 存储引擎
archive 存储引擎
myisam 存储引擎
innodb 存储引擎
mysql 相关操作
my.cnf 是 MySQL 的配置文件
登陆/退出 MySQL
登陆
mysql -uroot -p |
\h 主机
\u 当前登陆的用户
\d 当前打开的数据库
\D 当前服务器的日期时间
\c 取消当前命令的执行
help 或者\h 或者?加上相关关键字来查看手册
命令行结束符默认使用;或者\g 来结束
退出:exit | quit | \q | ctrl+c
MySQL 语句
SELECT USER() //得到登陆的用户 |
MySQL 常用函数
CEIL() 进一取整
FLOOR() 舍掉小数部分
ROUND() 四舍五入
TRUNCATE() 截取小数点后几位
MOD() 取余数
ABS() 取绝对值
POWER() 幂运算
PI() 圆周率
RAND()或者 RAND(X) 0~1 之间的随机数
SIGN(X) 得到数字符号
EXP(X) 计算 e 的 x 次方
数据库相关操作
创建数据库
CREATE {DATABASE|SCHEMA} db_name;
检测数据库名称是否存在,不存在则创建CREATE DATABASE [IF NOT EXISTS] db_name;
在创建数据库的同时指定编码方式CREATE DATABASE [IF NOT EXISTS] db_name [DEFAULT] CHARACTER SET [=] charset;查看当前服务器下全部数据库
SHOW DATABASES|SCHEMAS;查看指定数据库的详细信息
SHOW CREATE DATABASE db_name;修改指定数据库的编码方式
ALTER DATABASE db_name [DEFAULT] CHARACTER SET [=] charset;打开指定数据库
USE db_name;得到当前打开的数据库
SELECT DATABASE()|SCHEMA();删除指定的数据库
DROP DATABASE db_name;
如果数据库存在则删除DROP DATABASE [IF EXISTS] db_name;
MySQL 数据类型


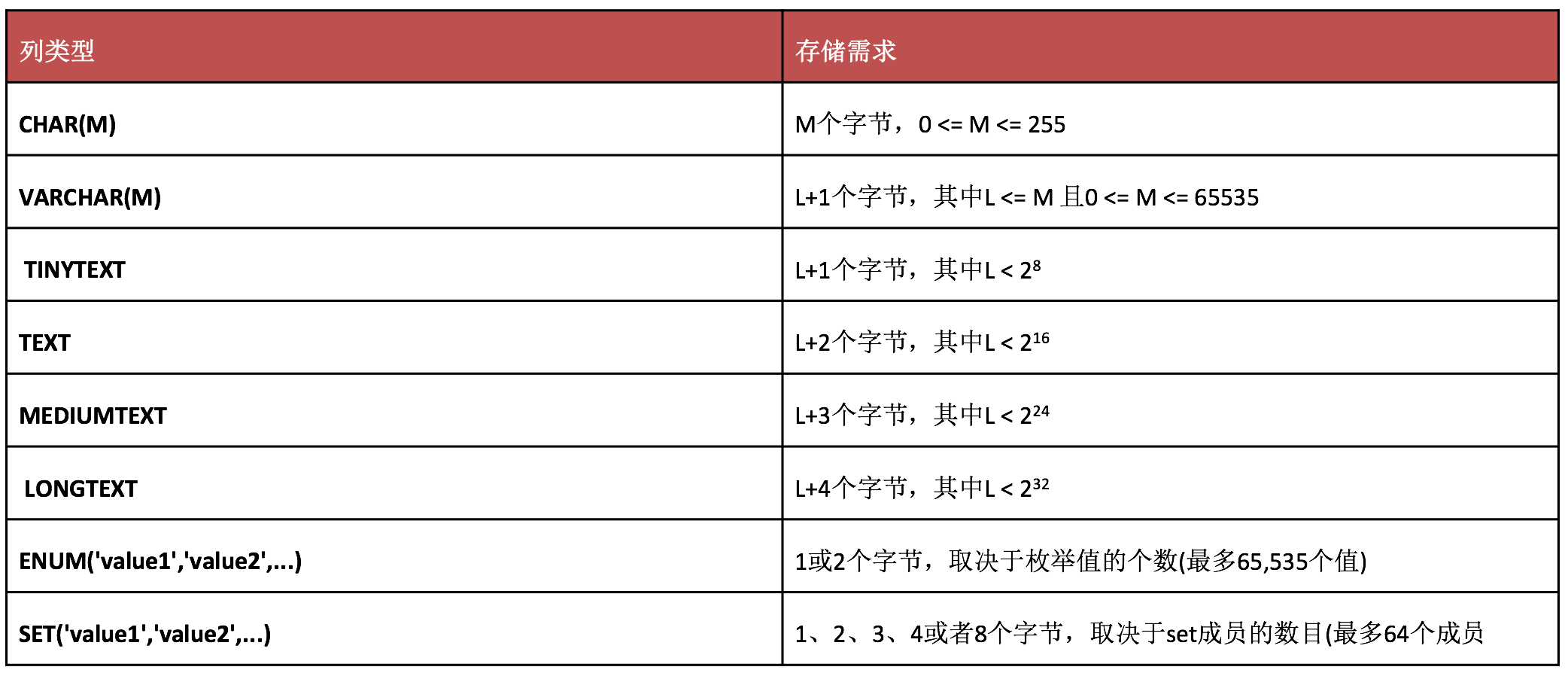
CHAR 效率高于 VARCHAR,CHAR 相当于拿空间换时间,VARCHAR 拿时间换空间
CHAR 默认存储数据的时候,后面会用空格填充到指定长度;而在检索的时候会去掉后面空格;VARCHAR 在保存的时候不进行填充,尾部的空格会留下
TEXT 列不能有默认值,检索的时候不存在大小写转换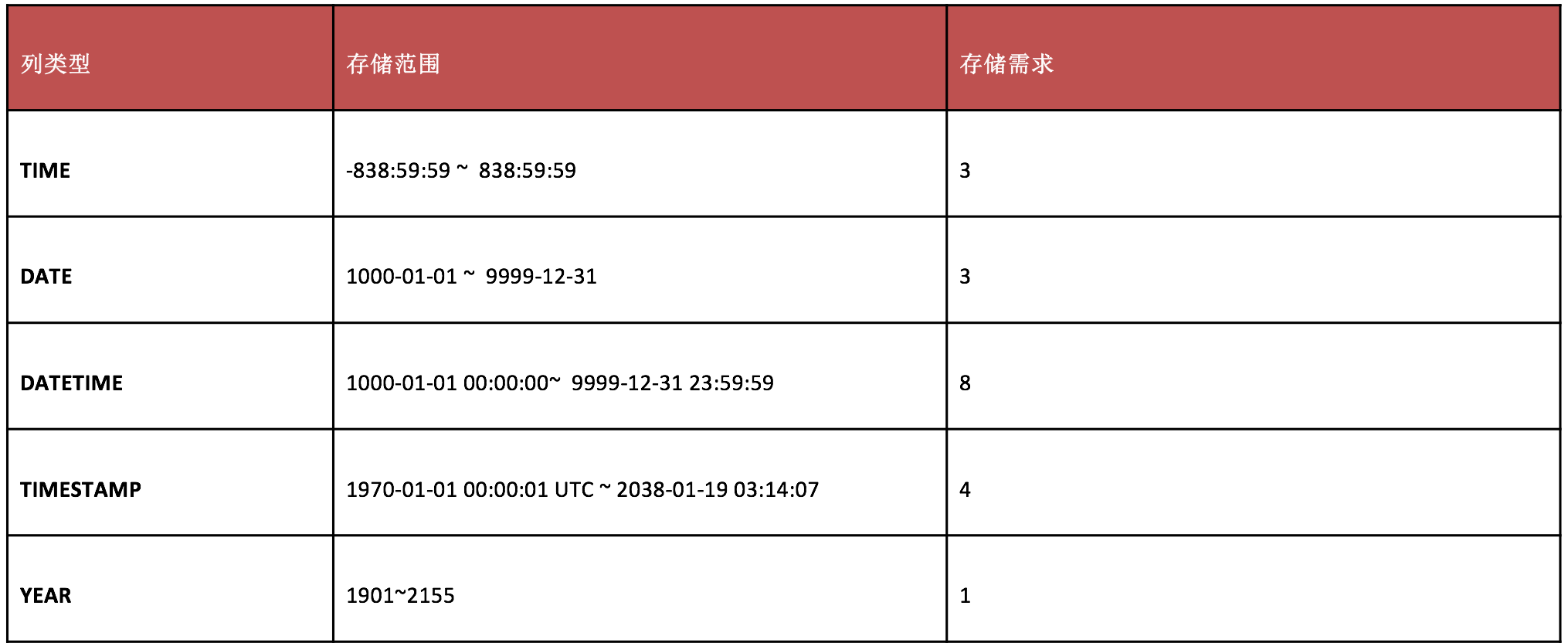
数据表相关操作
数据表:数据表由行(row)和列(column)来组成。每个数据表中至少有一列,行可以有零行一行或者多行组成。表名要求唯一,不要包含特殊字符,最好含义明确
- 创建表
CREATE TABLE [IF NOT EXISTS] tbl_name(
字段名称 字段类型 [完整性约束条件],
字段名称 字段类型 [完整性约束条件],
…
)ENGINE=存储引擎 CHARSET=编码方式;
约束条件
UNSIGNED 无符号,没有负数,从 0 开始
ZEROFILL 零填充,当数据的显示长度不够的时候可以使用前补 0 的效果填充至指定长度,字段会自动添加 UNSIGNED
NOT NULL 非空约束,也就是插入值的时候这个字段必须要给值,值不能为空
DEFAULT 默认值,如果插入记录的时候没有给字段赋值,则使用默认值
PRIMARY KEY 主键,标识记录的唯一性,值不能重复,一个表只能有一个主键,自动禁止为空
AUTO_INCREMENT 自动增长,只能用于数值列,而且配合索引使用,默认起始值从 1 开始,每次增长 1
UNIQUE KEY 唯一性,一个表中可以有多个字段是唯一索引,同样的值不能重复,但是 NULL 值除外
FOREIGN KEY 外键约束示例 1(无约束条件)
CREATE TABLE IF NOT EXISTS personal_info( |
- 示例 2(带约束条件)
CREATE TABLE IF NOT EXISTS `personal_info2`( |
- 要注意单引号和反引号的使用
- 查看当前数据库下已有数据表
SHOW TABLES;SHOW [FULL] TABLES [{FROM | IN} db_name] [LIKE 'pattern' | WHERE expr]; - 查看指定数据表的详细信息
SHOW CREATE TABLE tbl_name;
| personal_info2 | CREATE TABLE `personal_info2` ( |
- 查看表结构
DESC tbl_name;DESCRIBE tbl_name;SHOW COLUMNS FROM tbl_name;
+----------+------------------------+------+-----+---------+----------------+ |
- 删除指定的数据表
DROP TABLE [IF EXISTS] tbl_name;
表结构相关操作
add | drop | modify | change | set default | add/drop primary key | add/drop unique |rename
- 添加字段
ALTER TABLE tbl_nameADD 字段名称 字段属性 [完整性约束条件] [FIRST|AFTER 字段名称] - 删除字段
ALTER TABLE tbl_nameDROP 字段名称 - 添加默认值
ALTER TABLE tbl_nameALTER 字段名称 SET DEFAULT 默认值; - 删除默认值
ALTER TABLE tbl_nameALTER 字段名称 DROP DEFAULT - 修改字段类型、字段属性
ALTER TABLE tbl_nameMODIFY 字段名称 字段类型 [字段属性] [FIRST | AFTER 字段名称] - 修改字段名称、字段类型、字段属性
ALTER TABLE tbl_nameCHANGE 原字段名称 新字段名称 字段类型 字段属性 [FIRST | AFTER 字段名称] - 添加主键
ALTER TABLE tbl_nameADD PRIMARY KEY(字段名称) - 删除主键
ALTER TABLE tbl_nameDROP PRIMARY KEY; - 添加唯一
ALTER TABLE tbl_nameADD UNIQUE KEY|INDEX [index_name] (字段名称) - 删除唯一
ALTER TABLE tbl_nameDROP index_name; - 修改数据表名称
ALTER TABLE tbl_nameRENAME [TO|AS] new_tbl_nameRENAME TABLE tbl_name TO new_tbl_name; - 修改 AUTO_INCREMENT 的值
ALTER TABLE tbl_name AUTO_INCREMENT=值
数据内容相关操作
增加
INSERT [INTO] tbl_name[(col_name,...)] {VALUE|VALUES}(VALUES...);
- 不指定字段名称,需要按照建表时的字段顺序给每一个字段赋值
INSERT tbl_name VALUE(value...) - 列出指定字段
INSERT tbl_name(字段名称,...) VALUES(值,...) - INSERT … SET 的形式
INSERT tbl_name SET 字段名称=值,...; - INSERT … SELECT
INSERT tbl_name[(字段名称...)] SELECT 字段名称,... FROM tbl_name [WHERE 条件] 一次添加多条记录
INSERT tbl_name[(字段名称,...)] VALUES(VALUES,...),(VALUES,....),()...示例
-- 测试添加记录 |
删除
DELETE FROM tbl_name [WHERE 条件]
如果不添加条件,表中所有记录都会被删除
DELETE 清空数据表的时候不会重置 AUTO_INCREMENT 的值,可以通过 ALTER 语句将其重置为 1
TRUNCATE [TABLE] tbl_name;
清除表中所有记录
会重置 AUTO_INCREMENT 的值
- 示例
-- 测试删除语句 |
修改
UPDATE tbl_name SET 字段名称=值,字段名称=值 [WHERE 条件]
如果不添加条件,整个表中的记录都会被更新
- 示例
-- 测试修改语句 |
查询(重点)
SELECT select_expr,... FROM tbl_name [WHERE 条件] [GROUP BY {col_name|position} HAVING 二次筛选] [ORDER BY {col_name|position|expr} [ASC|DESC]] [LIMIT 限制结果集的显示条数]
查询表中所有记录SELECT * FROM tbl_name;
指定字段的信息SELECT 字段名称,... FROM tbl_name
库名.表名SELECT 字段名称,... FROM db_name.tbl_name;
给字段起别名SELECT 字段名称 [AS] 别名名称,... FROM db_name.tbl_name;
给数据表起别名SELECT 字段名称 ,... FROM tbl_name [AS] 别名;
表名.字段名的SELECT tbl_name.col_name,... FROM tbl_name;
- 示例
-- 查询表中所有记录 |
避免重复
关键词 DISTINCT 用于返回唯一不同的值。SELECT DISTINCT 列名称 FROM 表名称
- 示例
# 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t,对于重复的emp_no进行忽略。 |
where 条件
> >= < <= != <> <=> 比较运算符IS [NOT] NULL 检测值是否为 NULL 或者 NOT NULL[NOT] BETWEEN ... AND 指定范围[NOT] IN(值,...) 指定集合[NOT] LIKE 匹配字符% % 任意长度的字符串___ 任意一个字符
- 示例
SELECT id,username,age FROM user1 |
group by 分组
- GROUP_CONCAT()查看组中某个字段的详细信息
- 配合聚合函数使用
COUNT() //统计记录总数。如果写的是 COUNT(字段名称),字段中的值为 NULL,不统计进来,写 COUNT(*)会统计 NULL 值
SUM() //求和
MAX() //求最大值
MIN() //求最小值
AVG() //求平均值 - 配合
WITH ROLLUP关键使用,会在记录末尾添加一条记录,是上面所有记录的总和 HAVING子句对分组结果进行二次筛选
- 示例
-- 按照性别分组sex |
order by 排序
ORDER BY 字段名称 ASC|DESC
- 示例
-- 按照id降序排列 |
LIMIT 限制结果集显示条数
LIMIT 值
显示结果集的前几条记录
LIMIT offset,row_count
从 offset 开始,显示几条记录,offset 从 0 开始
- 示例
-- 显示结果集的前5条记录 |
多表查询
- 笛卡尔积的形式
- 内连接的形式
SELECT 字段名称,... FROM tbl_name1 INNER JOIN tbl_name2 ON 连接条件//查询两个表中符合连接条件的记录 - 外连接的形式
- 左外连接
SELECT 字段名称,... FROM tbl_name1 LEFT OUTER JOIN tbl_name2 ON 条件;
左表为主表,先显示左表中的全部记录,再去右表中查询复合条件的记录,不符合的以 NULL 代替 右外连接
SELECT 字段名称,... FROM tbl_name1 RIGHT [OUTER] JOIN tbl_name2 ON 条件;
右表为主表,先显示右表中的全部记录,再去左表中查询复合条件的记录,不符合的以 NULL 代替示例
-- 查询emp id username age addr dep id depName depDesc |
外键约束(loading…)
只有 InnoDB 存储引擎支持外键
- 建表时指定外键
[CONSTRAINT 外键名称 ]FOREIGN KEY(字段名称) REFERENCES 主表(字段名称)
子表的外键字段和主表的主键字段类型要相似;如果是数值型要求一致,并且无符号也要一致;如果是字符型,要求类型一致,长度可以不同
如果外键字段没有创建索引,MySQL 会自动帮我们添加索引
子表的外键关联的必须是父表的主键
- 外键约束的参照操作
CASCADE 从附表删除或更新,子表也跟着删除或者更新,级联的操作
SET NULL 从附表删除或者更新记录,并设置子表的外键列为 NULL。
NO ACTION | RESTRICT 拒绝对父表做更新或者删除操作
- 动态添加外键
ALTER TABLE tbl_name [CONSTRAINT 外键名称] ADD FOREIGN KEY(外键字段) REFERENCES 主表(主键字段);
动态添加外键之前表中的记录一定合法的记录,没有脏值,否则外键添加不成功 - 动态删除外键
ALTER TABLE tbl_name DROP FOREIGN KEY fk_name;
特殊形式查询(loading…)
子查询
SELECT 字段名称 FROM tbl_name WHERE col_name=(SELECT col_name FROM tbl_name)
联合查询
- UNION
SELECT 字段名称,... FROM tbl_name1 UNION SELECT 字段名称... FROM tbl_name2; - UNION ALL
SELECT 字段名称,... FROM tbl_name1 UNION ALL SELECT 字段名称... FROM tbl_name2;
UNION ALL 是简单的合并,UNION 会去掉表中重复记录
自身连接查询
正则表达式查询
^ 匹配字符串开始的部分$ 匹配字符串结束部分. 代表一个任意字符[字符集合] [abc] [a-z] [0-9][^字符集合] 除了集合中的内容s1|s2|s3 匹配 s1 或者 s2 或者 s3* 代表匹配前面的字符 0 次 1 次或者多次+ 代表匹配前面的字符至少出现 1 次字符{n} 前面的字符正好出现 n 次字符{m,n} 前面的字符至少出现 m 次,最多出现 n 次
其它注意事项
SQL 语句语法规范
- 常用 MySQL 的关键字我们需要大写,库名、表名、字段名称等使用小写
- SQL 语句支持折行操作,拆分的时候不能把完整单词拆开
数据库名称、表名称、字段名称不要使用 MySQL 的保留字,如果必须要使用,需要用反引号``将其括起来
创建的数据库名称最好有意义,名称不要包含特殊字符或者是 MySQL 关键字
常用 SQL 语句
- SHOW WARNINGS; //查看上一步操作产生的警告信息
- CHECK TABLE tbl_name //检测表
- REPAIR TABLE tbl_name //修复表
相关链接:
PHP & MySQL learning notes (4)
PHP & MySQL learning notes (3)
PHP & MySQL learning notes (2)
PHP & MySQL learning notes (1)
- 本文链接:https://hyqskevin.github.io/2019/02/15/mysql/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!